11月10日,国际低资源多语种语音识别竞赛OpenASR落下帷幕,科大讯飞-中科大语音及语言信息处理国家工程实验室(USTC-NELSLIP)联合团队(以下简称联合团队)参加了所有15个语种受限赛道和7个语种非受限赛道,并全部取得第一名的成绩!

继前不久荣获多语言理解评测XTREME冠军之后再次夺冠,意味着我们在实现人机交互更自然、人人沟通无障碍的探索征程中又迈出了坚实的一步,也为中国多语种语音语言技术的国际领先、中国智能制造的全球化奠定了坚实的基础。
持续进步:我们的领域,不止于大语种
近年来,深度学习技术的进步推动了中英等资源丰富语种的语音识别技术日趋成熟,并获得广泛的应用。
相比之下,由于语音数据资源难以标注,语言专家十分稀缺等原因,一些小语种语音识别系统距离实用门槛仍有较大差距。在此背景下,为探索低资源条件下的语音识别技术,OpenASR比赛应运而生——
OpenASR (Open Automatic Speech Recognition) 是由美国国家标准与技术研究院NIST(National Institute of Standards and Technology)于2020年发起,历届参赛团队众多,包含加拿大蒙特利尔信息科技研究中心、新加坡科技研究局、腾讯、清华大学等国内外知名研究机构和企业。
今年是第二次举办,比赛设置的主要目的是在多语种语音识别任务上探索如何使用少量的数据达到较好的效果,同时考察低资源语音识别基础算法在多个语种上的推广性。
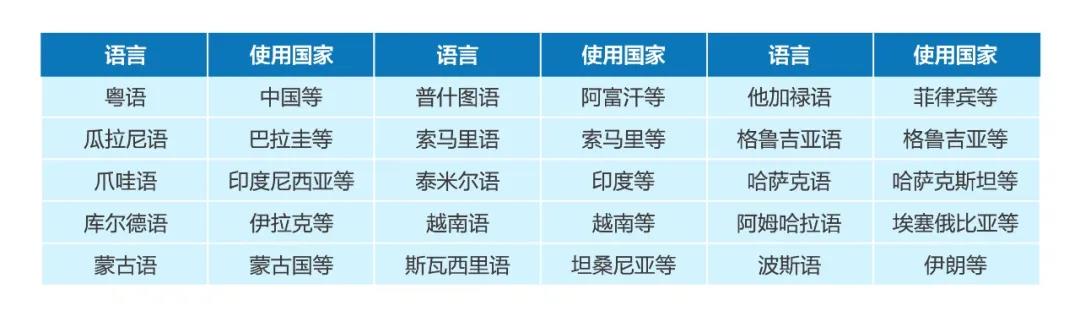
图1:15个语种信息
本次比赛共包含15个语种,涵盖受限赛道(Constrained condition)、受限附加赛道(Constrained Plus)和非受限赛道(Unconstrained Condition)。
其中受限赛道为各参赛单位必选项,每个语种只能使用组委会提供的10小时标注语音识别数据,受限附加赛道在受限赛道的基础上允许使用开源的预训练模型,而非受限赛道可以使用组委会提供10小时受限数据之外的数据。
联合团队提出了基于语音和文本统一空间表达的半监督语音识别框架(Unified Spatial Representation Semi-supervised ASR,USRS-ASR),得益于该算法良好的推广性,联合团队在受限赛道所有15个语种中全部取得冠军!同时,为了评估多语种语音识别实际应用水平,联合团队参加了7个语种非受限赛道,也全部取得第一名的成绩。
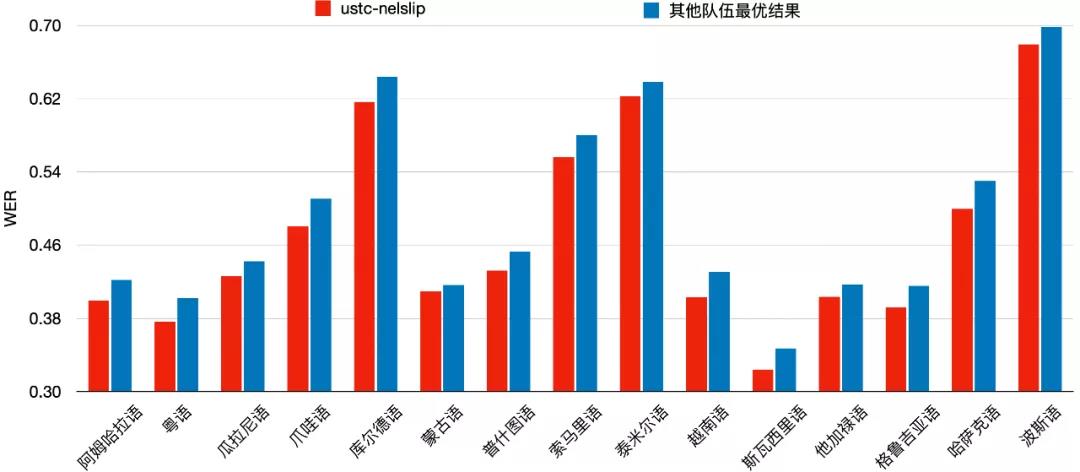
图2:联合团队全部15个语种受限赛道成绩
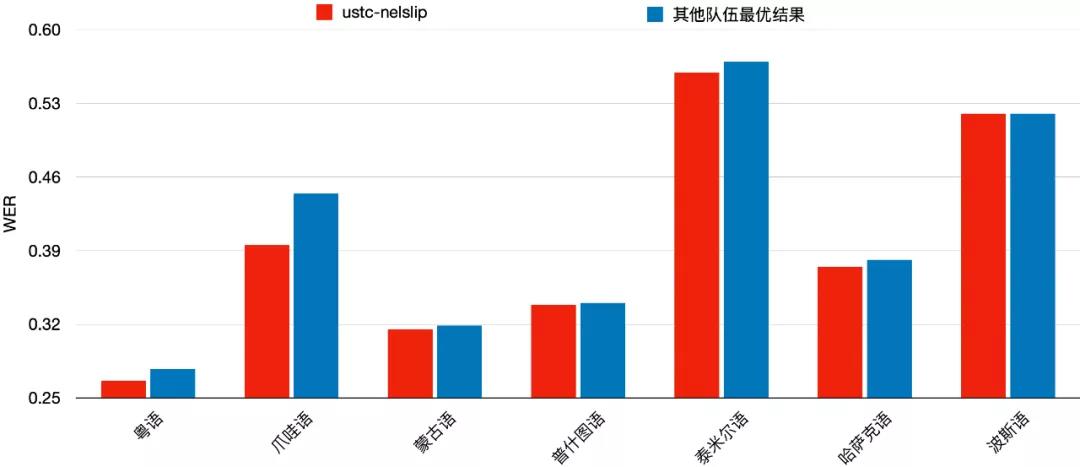
图3:联合团队参加的7个语种非受限赛道成绩
一场比赛,22个第一:这是不一般的难顶
比赛中,需要凭借仅有10个小时的低资源语音数据,来开发一套语音识别系统。而参赛团队面临的困难还不止于此——
对于低资源语种而言,除了语音数据量较小外,其发音词典大小、语料丰富性、标注准确度均远不及常规水平。
更不必说,本次比赛中各个语种数据主要来自电话信道,其对话风格非常自由,且口语化特征十分明显,都对资源受限条件下的语音识别系统提出了严峻的考验。
在受限赛道上,由于每个语种只有10小时语音数据,如何使用少量文本数据,利用无监督的方法增加语音训练数据的多样性至关重要。
联合团队创新性地使用了Flow-TTS语音合成进行训练数据扩增,并使用语音属性解耦技术保证合成语音的多样性。
结果显示,使用上述无监督数据扩增方案,低资源语音识别任务取得稳定、可观的效果提升。
最后,比赛提交系统在所有15个语种的受限赛道任务上全部拿下冠军。
而在非受限赛道上,同样也面临不小的挑战。
虽然参赛者可以利用公开数据,但业界公开的语音数据总量仍只有数百小时的量级。另外,语音数据和文本数据的量级差距十分明显,这对于端到端识别框架来说,弊端更为明显。
但联合团队相信,难顶也要上。
为了在端到端统一框架下,充分使用少量语音数据和海量文本数据,联合团队提出了基于语音和文本统一空间表达的半监督语音识别框架USRS-ASR。
首先,对于海量文本数据的使用,创新性的设计了文本掩码语言模型任务、合成数据语音识别两个目标,两个任务联合训练以充分利用海量无监督文本。
其次,设计了共享语言解码模块,实现了语音和文本隐层表达空间的统一。通过该框架,联合团队实现了对无监督文本的充分利用,大大缓解了低资源语种的数据稀疏问题。
最终,联合团队在提交的7个语种的非受限任务上,全部取得了第一名的成绩。
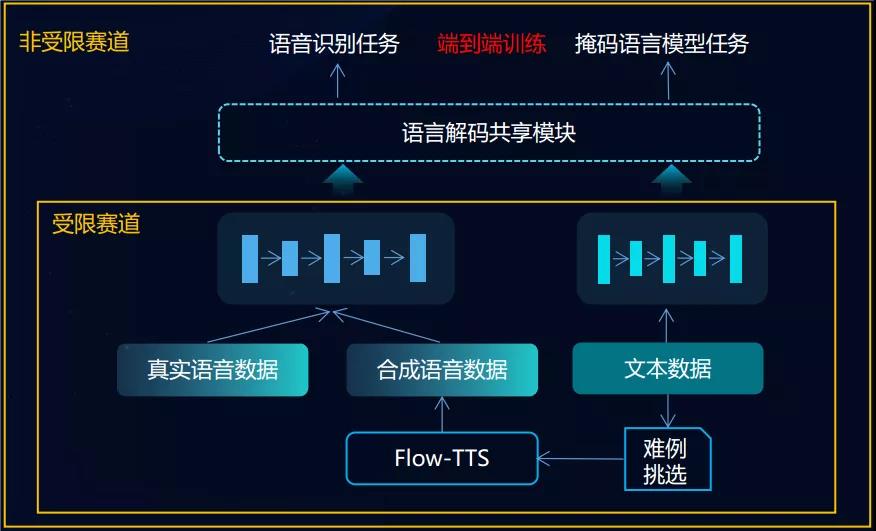
图4:USRS-ASR框架示意图
就这样,咱们的联合团队,顺利把22项“第一”收入囊中!也充分展现了,在低资源多语种语音识别技术上的地位实力。
技术应用在哪?我们正放眼全球
就在不久前,工信部正式批复同意成立国家智能语音创新中心、国家高端智能化家用电器创新中心,科技创新正不断引领产业升级。
值得注意的是,在这两家国家级创新中心依托公司的股东名单中,“科大讯飞”均赫然在列。
持续致力于打造源头技术创新策源地,科大讯飞正不断追寻“顶天立地”的产业梦想。
多语种语音语言技术是万物互联时代实现人机交互的关键技术,也是实现一带一路语言大互通的基础技术。
从2014年开始,我们就一直在该方向的源头技术创新及产业化应用上持续投入,并不断挑战实际应用中的技术难题。
经过多年的技术积累,除了中英以外,当前科大讯飞已经具备其他 69种语言的语音识别能力,其中已经有35个语种准确率已经超过90%,并已在新加坡、俄罗斯、印度、日本等国家部署了海外站点,将持续为海内外开发者提供语音识别、语音合成、机器翻译、图文识别等语音语言服务,所有服务均在科大讯飞开放平台开放。
多语种技术也有力支撑了科大讯飞智能硬件产品创新:
在翻译终端方面,2016年11月我们发布了翻译智能翻译硬件,开创了AI翻译机新品类;
在会议同传方面,2016年11月推出讯飞听见多语种字幕同传系统,目前支持日韩法西等多国语言的同声传译功能;
而在录音笔方面,2019年5月我们发布了智能录音笔,并在2020年5月升级支持8种语言转写能力,2021年日本版智能录音笔VOITER系列在日本一经上线,就取得单月超过千台的亮眼成绩。
除自身产品以外,科大讯飞也积极为手机、家电等中国智造国际化提供自主可控解决方案:
在手机、家电方面,为国内众多手机厂商提供包括中英在内的多语种语音识别、语音合成能力解决方案,并联合海尔研发多语种识别系统,助力其拓展东南亚市场;
在车载交互方面,与上汽、长安、奇瑞等国内主要出海汽车提供商,以及俄罗斯汽车工程研究院(NAMI)等海外车厂开展多语种项目合作,覆盖英语、俄语、日语、泰语、西班牙语、意大利语等数十个语种;
此外,我们的多语种相关技术能力也已经应用于北京2022年冬奥会官方APP(冬奥通),助力冬奥信息沟通无障碍。
图片
当前,人类已进入“人、机、物”智能互联时代,智能语音是这个时代最为关键的入口之一,有助于实现语言大互通,建设人类命运共同体。
在国际技术竞赛中的获奖,是我们22年如一日坚持创业初心、持续进行源头核心技术创新的努力注脚。
我们相信,这些岁月中对于创新的持之以恒,将不断助力中国语音识别技术参与全球竞争,让人工智能真正欣欣向荣、蓬勃向上、生生不息。
期待着,在未来中国大地上,人工智能鲜花怒放,而人类语言巴别塔也终将建成。



